SimpleDB
SimpleDB
Architecture and Implementation Guide
SimpleDB consists of:
- Classes that represent fields, tuples, and tuple schemas;
- Classes that apply predicates and conditions to tuples;
- One or more access methods (e.g., heap files) that store relations on disk and provide a way to iterate through tuples of those relations;
- A collection of operator classes (e.g., select, join, insert, delete, etc.) that process tuples;
- A buffer pool that caches active tuples and pages in memory and handles concurrency control and transactions (neither of which you need to worry about for this project); and,
- A catalog that stores information about available tables and their schemas.
SimpleDB does not include many things that you may think of as being a part of a “database.” In particular, SimpleDB does not have:
- (In this project), a SQL front end or parser that allows you to type queries directly into SimpleDB. Instead, queries are built up by chaining a set of operators together into a hand-built query plan . We will provide a simple parser for use in later projects.
- Views.
- Data types except integers and fixed length strings.
- (In this project) Query optimizer.
- Indices.
DataBase Class
Database类提供对静态对象集合的访问,这些静态对象是数据库的全局状态。包括访问目录Catelog(数据库中所有表的列表),缓冲池BufferPool(当前驻留在内存中的数据库文件页面的集合)和日志文件的方法。
Field and Tuple
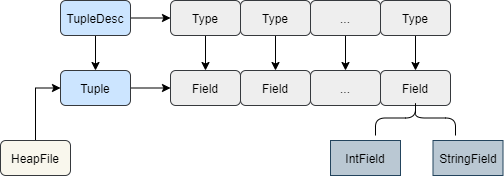
Tuple元组由Field字段组成,Field是个接口,有IntField和StringField两种实现,Tuple有一个字段称为TupleDesc,是描述元组的一个类,这个类有很多Type对象组成,每个Type和一个Field对应。
Tuple
有以下三个属性
private TupleDesc tupleDesc;
private RecordId recordId;
private Field[] fields;
recordId是对特定表的特定页面上的特定元组的引用。
看一下Iterator的写法
public Iterator<Field> fields() {
// some code goes here
return new FieldIterator();
}
private class FieldIterator implements Iterator<Field> {
private int pos = 0;
@Override
public boolean hasNext() {
return fields.length > pos;
}
@Override
public Field next() {
if (!hasNext()) {
throw new NoSuchElementException();
}
return fields[pos++];
}
}
TupleDesc
TupleDesc就是对Tuple元组的描述。
有以下属性值:
private int numFields;
private TDItem[] tdAr;
numFields很容易理解,就是Field的数目
tdAr是TDItem的数组,TDItem是TupleDesc的私有类,TDItem实现了Serializable接口,TDItem有以下属性:
Type fieldType;
String fieldName;
关于实现Serializable接口的用处,可以参考:https://zhuanlan.zhihu.com/p/40462507
序列化:把对象转化为可传输的字节序列过程称为序列化。
反序列化:把字节序列还原为对象的过程称为反序列化。
序列化后存储在硬盘上就是二进制文件了。
getSize()
TupleDesc有一个getSize()方法,用于获取一个tuple元组的大小(用字节表示),这个方法后面应该用得到。
/**
* @return The size (in bytes) of tuples corresponding to this TupleDesc.
* Note that tuples from a given TupleDesc are of a fixed size.
*/
public int getSize() {
// some code goes here
int totalSize = 0;
for (TDItem item : tdAr) {
totalSize += item.fieldType.getLen();
}
return totalSize;
}
Catalog
目录(SimpleDB中的Catalog类)由表的列表和数据库中当前存在的表的集合组成。
Catelog是个单例,我们要获取这个单例的时候用Datebase.getCatalog().
Catelog用四个哈希表来存储表的映射关系
private HashMap<Integer, DbFile> id2file;
private HashMap<Integer, String> id2pkey;
private HashMap<Integer, String> id2name;
private HashMap<String, Integer> name2id;
分别是表id到DbFile的映射,表id到主键的映射,表id到表名的映射以及表名到表id的映射等。
BufferPool
缓冲池(SimpleDB中的BufferPool类)负责在内存中缓存最近从磁盘读取的页面。所有操作符都通过缓冲池从磁盘上的各种文件读取和写入页面。它由固定数量的页面组成,由BufferPool构造函数的numPages参数定义。
BufferPool也是个单例,通过Database.getBufferPool()在全局获取到对应的单例。
HeapFile
HeapFile对象被组织成一组页面,每个页面由固定数量的字节存储,用于存储元组(由常量BufferPool.PAGE_SIZE定义),包括一个头。在SimpleDB中,数据库中的每个表都有一个HeapFile对象。 HeapFile中的每个页面都安排为一组槽(slot),每个槽(slot)可以容纳一个元组(SimpleDB中给定表的元组都具有相同的大小)。除这些插槽外,每个页面还有一个标头,该标头用一个位图表示,每个元组对应一个位。如果对应于特定元组的位为1,则表示该元组有效。如果为0,则该元组无效(例如,已被删除或从未初始化。)HeapFile对象的页面属于实现Page接口的HeapPage类型。页面存储在缓冲池中,但是由HeapFile类读取和写入。

有以下三个属性:
private File file;
private TupleDesc td;
private int numPages;
file就是heapfile对应的存储在硬盘上的文件了
numPages是当前file占用的page的数量,构造函数中有:
numPage = (int) (file.length() / BufferPool.PAGE_SIZE);
Each file consists of page data arranged consecutively on disk. Each page consists of one or more bytes representing the header, followed by the
BufferPool.PAGE_SIZE - header bytesbytes of actual page content. Each tuple requires tuple size * 8 bits for its content and 1 bit for the header. Thus, the number of tuples that can fit in a single page is:
tupsPerPage = floor((BufferPool.PAGE_SIZE * 8) / (*tuple size* 8 + 1))
每个文件由在磁盘上连续排列的页面数据组成。 每个页面由一个或多个表示header的字节组成,后跟BufferPool.PAGE_SIZE - header bytes 。 每个元组需要(元组大小* 8)的内存大小(用位表示)用于存储内容,1bit的大小用于表示头。 因此,可以在单个页面中容纳的元组数为:
tupsPerPage = floor((BufferPool.PAGE_SIZE * 8) / (*tuple size* 8 + 1))
接下来就是计算需要用于保存header位图的内存大小,用字节表示:
headerBytes = ceiling(tupsPerPage/8)
The low (least significant) bits of each byte represents the status of the slots that are earlier in the file. Hence, the lowest bit of the first byte represents whether or not the first slot in the page is in use. Also, note that the high-order bits of the last byte may not correspond to a slot that is actually in the file, since the number of slots may not be a multiple of 8. Also note that all Java virtual machines are big-endian.

To read a page from disk, you will first need to calculate the correct offset in the file. Hint: you will need random access to the file in order to read and write pages at arbitrary offsets. You should not call BufferPool methods when reading a page from disk.
You will also need to implement the
HeapFile.iterator()method, which should iterate through through the tuples of each page in the HeapFile. The iterator must use theBufferPool.getPage()method to access pages in theHeapFile. This method loads the page into the buffer pool and will eventually be used (in a later project) to implement locking-based concurrency control and recovery. Do not load the entire table into memory on the open() call — this will cause an out of memory error for very large tables.
readPage()方法是在当前HeapFile内实现的,也就是读取的是当前这个HeapFile里面的page。
此方法将页面加载到缓冲池中,并最终(在以后的项目中)将用于实现基于锁定的并发控制和恢复。不要在open()调用中将整个表加载到内存中-这将导致非常大的表出现内存不足错误.
/**
* 根据PageId从磁盘读取一个页,注意此方法只应该在BufferPool类被直接调用
* 在其他需要page的地方需要通过BufferPool访问。这样才能实现缓存功能
*
* @param pid
* @return 读取得到的Page
* @throws IllegalArgumentException
*/
public Page readPage(PageId pid) throws IllegalArgumentException {
// some code goes here
if (pid.getTableId() != getId()) {
throw new IllegalArgumentException();
}
Page page = null;
byte[] data = new byte[BufferPool.PAGE_SIZE];
try (RandomAccessFile raf = new RandomAccessFile(getFile(), "r")) {
// page在HeapFile的偏移量
int pos = pid.pageNumber() * BufferPool.PAGE_SIZE;
raf.seek(pos);
raf.read(data, 0, data.length);
page = new HeapPage((HeapPageId) pid, data);
} catch (IOException e) {
e.printStackTrace();
}
return page;
}
实现HeapFile.iterator()方法,这里移花接木了,其实用的是HeapPage.iterator()方法,就是用一个HeapFile里面的所有HeapPage的迭代器,迭代完一个页面就继续迭代下一个页面,需要注意的一点是不能用readPage()方法,因为这个是默认从磁盘中读取,而应该用BufferPool的getPage()方法,因为缓冲池实现了缓存管理,有些页面已经在内存中存在了,不用从磁盘中加载。
private class HeapFileIterator implements DbFileIterator {
private int pagePos;
private Iterator<Tuple> tuplesInPage;
private TransactionId tid;
public HeapFileIterator(TransactionId tid) {
this.tid = tid;
}
public Iterator<Tuple> getTuplesInPage(HeapPageId pid) throws TransactionAbortedException, DbException {
HeapPage page = null;
try {
page = (HeapPage) Database.getBufferPool().getPage(tid, pid, Permissions.READ_ONLY);
} catch (InterruptedException e) {
e.printStackTrace();
}
return page.iterator();
}
@Override
public void open() throws DbException, TransactionAbortedException {
pagePos = 0;
HeapPageId pid = new HeapPageId(getId(), pagePos);
//加载第一页的tuples
tuplesInPage = getTuplesInPage(pid);
}
@Override
public boolean hasNext() throws DbException, TransactionAbortedException {
if (tuplesInPage == null) {
//说明已经被关闭
return false;
}
//如果当前页还有tuple未遍历
if (tuplesInPage.hasNext()) {
return true;
}
//如果遍历完当前页,测试是否还有页未遍历
//注意要减一,这里与for循环的一般判断逻辑(迭代变量<长度)不同,是因为我们要在接下来代码中将pagePos加1才使用
//如果不理解,可以自己举一个例子想象运行过程
if (pagePos < numPages() - 1) {
pagePos++;
HeapPageId pid = new HeapPageId(getId(), pagePos);
tuplesInPage = getTuplesInPage(pid);
//这时不能直接return ture,有可能返回的新的迭代器是不含有tuple的
return tuplesInPage.hasNext();
} else return false;
}
@Override
public Tuple next() throws DbException, TransactionAbortedException, NoSuchElementException {
if (!hasNext()) {
throw new NoSuchElementException("not opened or no tuple remained");
}
return tuplesInPage.next();
}
@Override
public void rewind() throws DbException, TransactionAbortedException {
//直接初始化一次。。。。。
open();
}
@Override
public void close() {
pagePos = 0;
tuplesInPage = null;
}
}
HeapPageId
Unique identifier for HeapPage objects.
两个属性:
private int tableId;
private int pageNum;
pageNum是对应的table中页面的顺序号。
HeapPage
有以下属性:
private HeapPageId pid;
private TupleDesc td;
private byte header[];
private Tuple tuples[];
private int numSlots;
private TransactionId lastDirtyOperation;
获取对应的tuple数量的方法:
private int getNumTuples() {
if (numSlots != 0) {
return numSlots;
}
//int的四则运算就是向下取整的
numSlots = (BufferPool.PAGE_SIZE * 8) / (td.getSize() * 8 + 1);
return numSlots;
}
同样地,获取header头部的大小:
private int getHeaderSize() {
// some code goes here
return (int) Math.ceil(getNumTuples() / 8.0);
}
在插入tuple之后,需要将对应的slot置为1,删除tuple之后则需要将其置为0,因此有一个方法如下:
/**
* 将某个slot的值改为1或0
* Abstraction to fill or clear a slot on this page.
*/
private void markSlotUsed(int i, boolean value) {
// some code goes here
// not necessary for lab1
int byteNum = i / 8;//计算在第几个字节
int posInByte = i % 8;//计算在该字节的第几位,从右往左算(这是因为JVM用big-ending)
header[byteNum] = editBitInByte(header[byteNum], posInByte, value);
}
editBitInByte()方法是为了改变一个字节中某个字位,方法如下:
/**
* 修改一个byte的指定位置的bit
*
* @param target 待修改的byte
* @param posInByte bit的位置在target的偏移量,从右往左且从0开始算,取值范围为0到7
* @param value 为true修改该bit为1,为false时修改为0
* @return 修改后的byte
*/
private byte editBitInByte(byte target, int posInByte, boolean value) {
if (posInByte < 0 || posInByte > 7) {
throw new IllegalArgumentException();
}
byte b = (byte) (1 << posInByte);//将1这个bit移到指定位置,例如pos为3,value为true,将得到00001000
//如果value为1,使用字节00001000以及"|"操作可以将指定位置改为1,其他位置不变
//如果value为0,使用字节11110111以及"&"操作可以将指定位置改为0,其他位置不变
return value ? (byte) (target | b) : (byte) (target & ~b);
}
isSlotUsed()提供了判断slot是否为空的方法:
public boolean isSlotUsed(int i) {
// some code goes here
//注意使用的是big-ending
//例如有18个slots,而且全是used的,那么header的二进制数据为[11111111, 11111111, 00000011]
//最后一个byte的前面六个0并不对应slot
int byteNum = i / 8;//计算在第几个字节
int posInByte = i % 8;//计算在该字节的第几位,从右往左算(这是因为JVM用big-ending)
return isOne(header[byteNum], posInByte);
}
/**
* @param target 要判断的bit所在的byte
* @param posInByte 要判断的bit在byte的从右往左的偏移量,从0开始
* @return target从右往左偏移量pos处的bit是否为1
*/
private boolean isOne(byte target, int posInByte) {
// 例如该byte是11111011,pos是2(也就是0那个bit的位置)
// 那么只需先左移7-2=5位即可通过符号位来判断,注意要强转
return (byte) (target << (7 - posInByte)) < 0;
}
这个方法就是上面谈及大端序的一个应用,正是因为字节序是大端的,看例子的第18个slot才会位于第2个字节处(基0),因为大端序中高位字节是存储在低位地址中,刚好就是[11111111,11111111,00000011]这种格式。
Operators
操作符负责查询计划的实际执行。它们实现关系代数的运算。在SimpleDB中,运算符是基于迭代器的;每个操作员都实现DbIterator接口。通过将较低级别的运算符传递到较高级别的运算符的构造函数中,即通过“将它们链接在一起”,将运算符连接在一起成为一个计划。查询计划末尾的特殊访问方法运算符负责从磁盘读取数据(因此,它们下面没有任何运算符)。
在计划的顶部,与SimpleDB交互的程序只需在root运算符上调用getNext。然后,此运算符在其子级上调用getNext,依此类推,直到调用了这些叶子运算符为止。他们从磁盘上获取元组,并将它们传递到树上(作为getNext的返回参数);元组以这种方式在计划中向上传播,直到它们从根输出或被计划中的另一个运算符合并或拒绝为止。
DbIterator
DbIterator是所有SimpleDB操作符应实现的迭代器接口。 如果迭代器未打开,则所有方法均不起作用,并且不应引发IllegalStateException。 除了进行任何资源分配/取消分配之外,open方法还应调用任何子迭代器的open方法,而在close方法中,迭代器应调用其子项的close方法。
DbIterator中有以下抽象方法:
void open();
boolean hasNext();
Tuple next();
//Resets the iterator to the start.
void rewind();
TupleDesc getTupleDesc();
SeqScan
该运算符从构造函数中的tableid指定的表的页面顺序扫描所有元组。该运算符应通过DbFile.iterator()方法访问元组。
private static final long serialVersionUID = 1L;
private TransactionId tid;
private int tableid;
private String tableAlias;
private DbFileIterator tupleIterator;
private TupleDesc td;
构造函数:
public SeqScan(TransactionId tid, int tableid, String tableAlias) {
// some code goes here
this.tid = tid;
this.tableAlias = tableAlias;
this.tableid = tableid;
tupleIterator = Database.getCatalog().getDbFile(tableid).iterator(tid);
}
构造函数从一个指定transaction事务中指定的table上创建一个序列扫描实例。
从整个类来看,SeqScan的open(),rewind(),hasNext()和next()方法都是调用了tupleIterator的open(),rewind(),hasNext()和next()方法。
tupleIterator是个DbFileIterator实例,DbFileIterator是个接口,注释中描述如下:
DbFileIterator is the iterator interface that all SimpleDB Dbfile should implement.
下面这个测试串起了proj1的所有类,可以加深对整个项目结构的理解:
package simpledb;
import java.io.*;
public class test {
public static void main(String[] argv) {
// construct a 3-column table schema
Type types[] = new Type[]{ Type.INT_TYPE, Type.INT_TYPE, Type.INT_TYPE };
String names[] = new String[]{ "field0", "field1", "field2" };
TupleDesc descriptor = new TupleDesc(types, names);
// create the table, associate it with some_data_file.dat
// and tell the catalog about the schema of this table.
HeapFile table1 = new HeapFile(new File("some_data_file.dat"), descriptor);
Database.getCatalog().addTable(table1, "test");
// construct the query: we use a simple SeqScan, which spoonfeeds
// tuples via its iterator.
TransactionId tid = new TransactionId();
SeqScan f = new SeqScan(tid, table1.getId());
try {
// and run it
f.open();
while (f.hasNext()) {
Tuple tup = f.next();
System.out.println(tup);
}
f.close();
Database.getBufferPool().transactionComplete(tid);
} catch (Exception e) {
System.out.println ("Exception : " + e);
}
}
}本文出自:https://www.cnblogs.com/zhengxch/p/14901516.html