The preceding article explained how re2c can be used to split text into a series of tokens. This article explains how a Lemon-generated parser can use those tokens to analyze text structure. To demonstrate how Lemon is used, this article’s example involves generating a parser for an abridged version of the C programming language.
A parser generated by Lemon performs LALR(1) parsing, where LALR stands for Look Ahead Left-to-Right. This means it matches rules to token sequences by looking ahead at most one token. This parser executes quickly, and the SQLite project relies on a Lemon-generated parser to analyze SQL commands.
1. Preliminary Concerns
This article adopts a hands-on approach in explaining how to generate parsing code with Lemon. To understand this article, you don’t need to be familiar with parsing theory. But you should have a firm grasp of C programming.
The example code presented in this article has been compiled with gcc. However, it should be usable with any C/C++ build system.
One more thing. Many computer scientists take the topic of parsing deathly seriously. I’m not one of those people, so don’t be upset or surprised if the content of this article lacks the academic rigor you’d expect in a professional publication.
2. Overview of Lemon Usage
Like re2c, Lemon is freely available. Its main site provides source code (lemon.c and lempar.c) and a link to the tool’s documentation. To use Lemon, lemon.c needs to be compiled into an executable with a command such as the following:
gcc -o lemon lemon.c
The lemon executable accepts the name of a grammar file, whose suffix is usually *.y or *.yy. As the executable runs, it examines the content of the grammar file and generates parser code. For example, the following command accepts a grammar file called simple_c_grammar.y:
lemon simple_c_grammar.y
This executable will only work properly if lempar.c is in the working directory. If it completes successfully, Lemon will produce three output files:
- simple_c_grammar.c – The parser source code
- simple_c_grammar.h – A header file that defines token values
- simple_c_grammar.out – Text file that describes the parser’s operation
The *.c file contains functions that make it possible to execute the parser. Before I discuss those functions, I want to explain how to write a grammar file.
3. Writing a Grammar File
A Lemon grammar file consists of two types of statements:
- Rules – construct grammar patterns (symbols) from other symbols and optionally execute C code
- Directives – configure Lemon’s operation, each directive starts with
%
These statements can appear in any order. This section discusses both types of statements, but before I get into the details, I want to discuss the example programming language.
3.1 The SimpleC Programming Language
To demonstrate how Lemon is used, this article explains how to generate a parser for an abridged version of C called SimpleC. This has the same syntax as the C language we know and love, but excludes many features including custom types, if–then–else statements, and preprocessor directives.
The following statements give a basic idea of how SimpleC programs are structured:
- A program consists of declarations/definitions of functions and/or variables.
- A variable declaration consists of a data type, one or more identifiers separated by commas, optional initializations, and a semi-colon.
- A function definition consists of an optional type, an identifier, parentheses surrounding an optional parameter list, and a block of code within curly braces.
These rules don’t cover all of SimpleC, but the structure of every program can be boiled down to similar rules. As a result, the structure of every SimpleC program can be expressed using a tree structure called an abstract syntax tree (AST).
For example, consider the following SimpleC program:
int x = 0; main() { while(x < 5) { x = x+1; } }
Figure 1 gives an idea what an AST for this program might look like. As shown, ASTs don’t include punctuation such as parentheses, braces, and semicolons.
Figure 1: An Example Abstract Syntax Tree
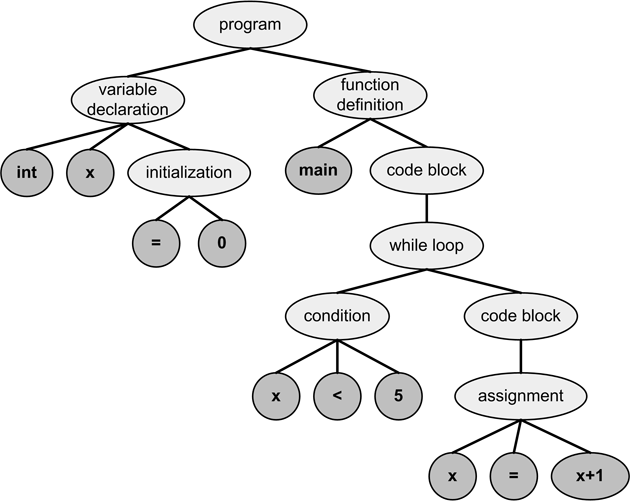
In this tree, the nodes without children contain characters (tokens) formed directly from the program’s text. These dark-gray nodes are called terminal symbols because they appear at the end of each branch.
The light-gray nodes are nonterminal symbols, and they’re formed by combining their children together. The root node of the tree represents the entire program. In this simple example, the program consists of one variable declaration and one function definition, so the topmost node has two children.
3.2 Rules
Earlier, I presented statements that describe the high level structure of a SimpleC program. The purpose of a grammar file is to express those statements in a form that Lemon can understand. These statements are called rules, and each rule forms a nonterminal symbol from one or more symbols.
The general form of a rule in a Lemon grammar file is given as follows:
nonterminal_symbol ::=
expression. {
code
}Here, expression is a combination of zero or more symbols. { code } is an optional block of code to execute when the parser creates the nonterminal symbol.
By default, Lemon expects that the first rule’s nonterminal symbol corresponds to the root of the syntax tree. For example, the following rule prints text to the console when the program symbol is created from the declarations symbol:
program ::= declarations. { printf("Constructed the root symbol!\n"); }
Lemon supports recursion, so a nonterminal symbol can be included on both sides of the rule. Lemon’s documentation recommends left-recursion, and the following rules state that a declarations symbol may contain one or more declaration symbols:
declarations ::= declarations declaration. declarations ::= declaration.
A grammar file may contain multiple rules for same nonterminal symbol. When this happens, Lemon checks all of the rules and forms the symbol if any rule applies. Put another way, Lemon doesn’t support ORing expressions with ‘|’, so it’s necessary to write a new rule for each alternative.
So far, every nonterminal symbol has been written in lowercase. This isn’t just a convention. Lemon distinguishes nonterminal symbols from terminal symbols by checking the case of the first letter: lowercase implies a nonterminal symbol and uppercase implies a terminal symbol. In general, terminal symbols are written in all caps.
For example, the following rule states that a nonterminal symbol representing an enum statement can be formed from an ENUM terminal symbol, a NAME terminal symbol, an LBRACE terminal symbol, an enumerator_list nonterminal symbol, and an RBRACE terminal symbol.
enum_specifier ::= ENUM NAME LBRACE enumerator_list RBRACE.
The ENUM, NAME, LBRACE, and RBRACE terminal symbols correspond to the ENUM, NAME, LBRACE, and RBRACE tokens provided by the lexer. Later in the article, I’ll explain how to connect the output of an re2c-generated lexer to the input of a Lemon-generated parser.
3.3 Directives
As mentioned earlier, Lemon assumes that the nonterminal symbol created by the first rule in the grammar file is the topmost node in the syntax tree. But if the program symbol should be the topmost node, the following statement should be added:
%start_symbol program
%start_symbol is a directive that configures how the Lemon-generated parser operates. Table 1 lists this and other directives:
| Directive | Description |
|---|---|
%start_symbol |
The symbol to serve as the top of the syntax tree |
%token_prefix |
Adds a prefix to the names in the header file |
%name |
Change the names of generated functions |
%token_type |
Data type of each token |
%token_destructor |
Destructor code for terminal symbols |
%type |
Data type of nonterminal symbols |
%destructor |
Destructor code for nonterminal symbols |
%include |
Code to be inserted at the top of the parser |
%left |
Assign left-associative precedence values |
%right |
Assign right-associative precedence values |
%nonassoc |
Assigns non-associative precedence |
%parse_accept |
Code to execute after successful parse |
%parse_failure |
Code to execute after unsuccessful parse |
%syntax_error |
Code to execute after syntax error |
%stack_size |
Sets the size of the parser’s stack |
%stack_overflow |
Code to execute if stack exceeds size |
%extra_argument |
Allows Parse to be called with a fourth parameter |
When Lemon generates a parser, it also generates a header file that associates each terminal symbol with a number (similar to tokens.h in the re2c example). By default, Lemon will use the names given in the rules (LPAREN will be LPAREN in the header file, INT will be INT, and so on). But if %token_prefix is associated with text, that text will be prepended to each macro in the header file.
For example, the following directive tells Lemon to prepend TK_ to each token name in the generated header file.
%token_prefix TK_
The %name directive is similar, but instead of changing token names, it changes the names of the parser’s interface functions. As I’ll explain shortly, the functions that access the parser all start with Parse by default. But if %name is associated with a string, the functions will start with that string instead.
The %token_type directive is quite different than %token_name. As will be explained, when a parser receives a token from the lexer, it can also receive a structure containing data. For example, if the parser needs to read identifier names using one-byte values, the token’s value can be set to a char* with the following directive:
%token_type { char* }
If special code needs to be executed when the tokens’ data structures are destroyed, the code block can be associated with the %token_destructor directive. The %type and %destructor directives are similar to %token_type and %token_destructor, but they relate to nonterminal symbols instead of terminal symbols.
If a code block is associated with %include, Lemon will insert the code at the top of the generated parser code. For this reason, this code block usually contains #include statements and declarations of custom data structures. This is shown by the following directive:
%include {
#include <assert.h>
}
4. Interfacing the Parser with re2c
If simple_c_grammar.y is a suitable grammar file, the following command generates parser code in a file called simple_c_grammar.c:
lemon simple_c_grammar.y
The code in simple_c_grammar.c contains four functions that enable applications to access the parser. Table 2 lists the functions and provides a description of each:
| Function | Description |
|---|---|
ParseAlloc(malloc_func) |
Allocates the parser structure using the routine and returns a pointer to the parser |
Parse(void* parser, int token_id,Custom Type tokenData) |
Sends the token to the parser |
ParseFree(void* parser, free_func) |
Deallocates the parser using the given routine |
ParseTrace(FILE* fp, char* trace) |
Enables parser tracing by providing a stream |
These functions are straightforward to use and understand. ParseAlloc accepts a function that should be used to allocate memory (usually malloc) and returns a pointer to the parser. The parser’s data type isn’t important, so applications usually treat the returned pointer as a void pointer, as shown in the following code:
void* parser = ParseAlloc(malloc);
In the Parse function, the first argument is the parser and second argument identifies the token identifier (LPAREN, WHILE, FOR, and so on), which should be an integer. The third argument is a data structure corresponding to the token. Its data type is set with the %token_type directive presented earlier.
The re2c example code calls the scan function in a loop. Each iteration of the loop corresponds to a token from the input text. The following code calls Parse inside the loop to send each token to the parser as it’s received. No data is sent with the token, so the third argument is set to NULL.
while(token = scan(&scanner, buff_end)) {
Parse(parser, token, NULL);
}
After the lexer sends the last token to the parser, it needs to call Parse one more time. In this case, the token ID should be set to zero and the token value should be set to NULL. I’m not sure why this is necessary, but the parser won’t complete successfully without it. The following code shows how this works:
Parse(parser, 0, NULL);
When the parser is no longer needed, it can be destroyed with the ParseFree method. This accepts the void pointer returned by ParseAlloc and the name of the deallocation routine to use for deallocation (usually free).
4.1 Sending/Receiving Token Data
It’s common for the lexer to send data along with a Token ID. For example, the lexer may pass strings corresponding to the identifier tokens (NAME). This means setting %token_type to the data type for characters (such as char*) and setting the third parameter of the Parser function to the string. The following code shows one way this can be accomplished:
int token, name_length; char* name_str; if(token == NAME) { // Get the length of the identifier name_length = scanner.cur - scanner.top; // Allocate memory and copy the identifier from the scanner name_str = (char*)malloc(name_length * sizeof(char)); strncpy(name_str, scanner.top, name_length); name_str[name_length + 1] = '\0'; // Send the token and the string to the parser Parse(parser, token, name_str); // Free the allocated memory free(name_str); } else { Parse(parser, token, ""); }
The parser can access this value by following the corresponding terminal symbol with a variable name inside parentheses. In the following rule, the code prints the value of the str variable associated with the NAME symbol:
direct_declarator ::= NAME(str). { printf("The identifier is %s\n", str); }
Nonterminal symbols can also have associated values. The following code associates the direct_declarator symbol with the value from the NAME token:
direct_declarator(strB) ::= NAME(strA). { strB = strA; }
Similar code can be used to pass data between rules. Another method is to call the Parse function with an extra argument. This is the topic of the following discussion.
4.2 Extra Argument
Lemon doesn’t allow global variables to be set in a grammar file. This helps to ensure thread safety, but it makes it hard for different rules to access the same data. To enable global data access, Lemon allows the lexer to add an optional fourth argument to the Parse function.
This extra argument can have any type, and it’s enabled by setting %extra_argument to a block containing the argument’s type and a variable name. In the SimpleC example grammar, the fourth argument of Parse allows the application to count the number of declarations and function definitions. This argument is a pointer to a ParserCount structure, which is defined in the following way:
typedef struct ParserCount { int numFunctionDefinitions; int numVariableDeclarations; } ParserCount;
The lexer creates a ParserCount, initializes its fields, and sends it to the parser with the following code:
Parse(parser, token, "", &pCount);
In the grammar file, the ParserCount structure is defined in the %include directive so that it will be inserted at the top of the generated code. The following directive enables the pCount variable to be accessed throughout the parser:
%extra_argument { ParserCount *pCount }
The following rules access pCount to increment the number of function definitions and variable declarations:
external_declaration ::= function_definition. { pCount->numFunctionDefinitions++; }
external_declaration ::= declaration. { pCount->numVariableDeclarations++; }
The extra argument can be set equal to the value of the top-level nonterminal symbol. This value is a pointer to the syntax tree corresponding to the input text.
5. Error Handling
If the parser completes its analysis without error, Lemon will execute the code block associated with the %parse_accept directive. If an error occurs, Lemon executes the code associated with %syntax_error. Afterward, it backtracks until it reaches a state where it can shift a nonterminal symbol called error. Then it attempts to continue parsing normally.
If the parser backtracks all the way to the beginning and can’t shift the error symbol, it executes the code associated with the %parse_failed directive. Then it resets itself to its start state.
In my experience, the most useful tool for detecting errors is the ParseTrace function from Table 2. This prints messages to a stream that describe the parser’s current state. For example, the following code tells Lemon to print state messages to a file pointer called traceFile and precede each message with “parser >>“.
ParseTrace(traceFile, "parser >>");
As the parser runs, it prints messages such as the following:
parser >> Input 'LPAREN' parser >> Reduce [direct_declarator ::= NAME], go to state 92. parser >> Shift 'direct_declarator', go to state 135 parser >> Shift 'LPAREN', go to state 58 parser >> Return. Stack=[external_declaration_list declaration_specifiers direct_declarator LPAREN]
If the parser reaches a syntax error, it provides alert messages.
parser >> Shift 'logical_or_expression', go to state 141 parser >> Reduce [conditional_expression ::= logical_or_expression], go to state 41. parser >> Shift 'conditional_expression' parser >> Reduce [constant_expression ::= conditional_expression], go to state 41. parser >> Shift 'constant_expression', go to state 179 parser >> Syntax Error!
By examining these messages, the application can get an idea of where the error occurred. It’s also a good idea to use %syntax_error with the extra argument of Parse to notify the lexer in the event of a syntax error.
6. Using the code
The code for this article generates a parsing application for SimpleC. It’s provided in an archive called lemon_demo.zip, which contains four files:
- simple_c.re – lexer definition file, re2c can use this to generate a lexer
- simple_c_grammar.y – SimpleC grammar file, Lemon can use this to generate parsing code
- test.dat – Contains C code that can be successfully parsed
- Makefile – Contains instructions for generating the lexer and parser and building the application
If you have GNU’s make and gcc utilities, you can execute the make command. This reads the Makefile instructions and automatically builds the application.
If you want to build the application manually, you need to perform three steps:
- Use Lemon to generate parser code from the grammar (
lemon simple_c_grammar.y) - Use re2c to generate the lexer code (
re2c -o simple_c.c simple_c.re) - Compile the lexer and parser code (
gcc -o simple_c simple_c.c simple_c_grammar.c)
The application parses the code in test.dat. In addition to printing messages to standard output, it uses ParseTrace to print state messages to trace.out.

admin:支持一下,感谢分享!,+5,