本次介绍一篇阿里采用图卷积对闲鱼垃圾评论进行识别的文章《 Spam Review Detection with Graph Convolutional Networks 》,本篇文章是非常值得一读的工业向论文。垃圾文本内容识别属于内容安全的一个重要方面,一般的方法是采用Naive Beyes、TextCNN等模型从文本角度进行识别,但是垃圾评论变异太快,文本模型对抗起来非常困难。该文结合了行为层面的信息,通过构建GCN模型对闲鱼的垃圾评论进行识别。
一、背景
在垃圾文本识别中,我们常常遇到以下挑战,模型对抗有比较大的难度:
- 换个说法(camouflage):使用不同的方式表达相同的意思,例如「拨打电话获得更多兼职信息」和「闲余时间挣点钱?联系我」,这两者都引导我们关注相同的兼职广告。
- 关键字替换(deform):使用少见的中文字符、笔误、表情符号替换关键字,例如「加我的 VX/V/WX」都表示加我的微信。
垃圾文本识别是一个典型的二分类问题。闲鱼开发了一套GCN-based Anti-Spam System(GAS) 的垃圾评论过滤系统,采用图卷积技术对闲鱼商品评论中的垃圾文本进行识别。
二、异构图抽取实体embedding向量
1、二部图构建(Xianyu Graph)
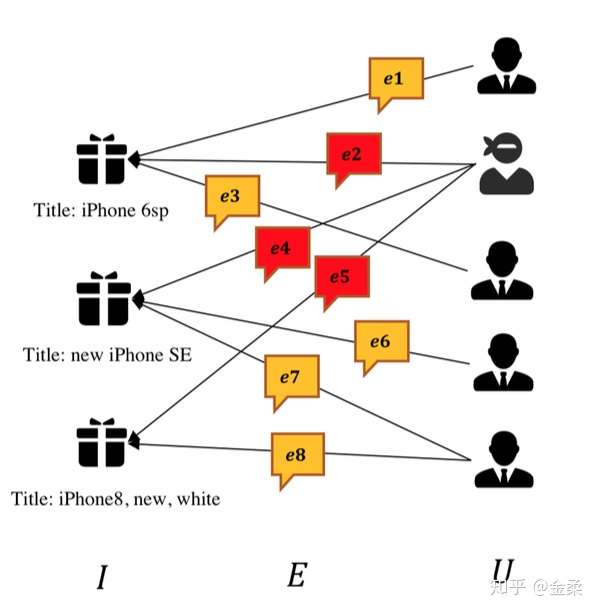
将商品I和用户(买家)U看做两类节点,它们的边为评论E(u对i有评论,则两个节点形成一条边)。
2、生成(初始化)节点和边特征
- 用户和商品特征
- 评论:采用word2vec为词向量输入的TextCNN模型,需要注意这里不是另外训练一个TextCNN模型,而是将该模型参数和GCN结构共同训练。
3、batch-size采样
batch-size的采样方法是:
假设在一个batch内选择了e0,e1,e2三个评论,对于e0找到对应的u0和i0,分别按照两条MetaPath:I->U->I和U->I->U进行采样。
需要注意的是,这里的采样方法和GraphSage存在一些区别。若邻居数量大于采样数M,那么挑选最接近的M个邻居,这里区别于GraphSage的随机采样,
本文出自:https://zhuanlan.zhihu.com/p/103476773